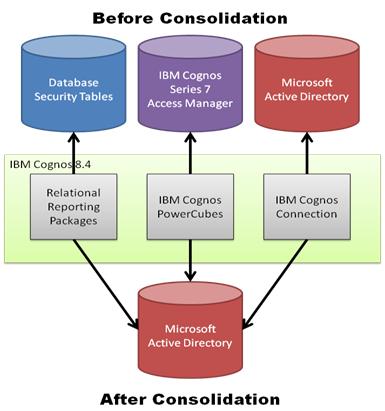
For those starting out with Cognos 8, or even those who have worked with it for quite a while, Framework Manager model design can seem like a daunting or even overwhelming task. With so many options available, it can be hard to know what to consider during design, and how to promote stability and sustainability.
This is the first in a two-part article that will focus on the best practices, organization and overall methodology of Framework model development. As is often the case with complex tools, even developers who have worked with Cognos for a while can be confused on at least some of the concepts and considerations of model design. The focus of this first article will start from the beginning, and describe an overall 4 layer approach, detailing the purpose and reason for each of the four layers. Next month’s article will describe advanced best practices, and other tips.
Four Layer Approach
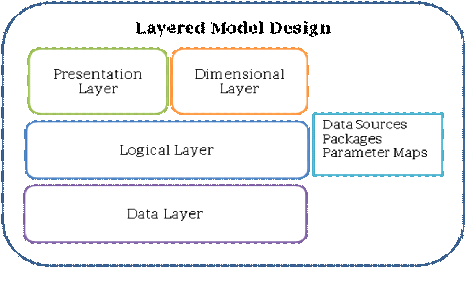
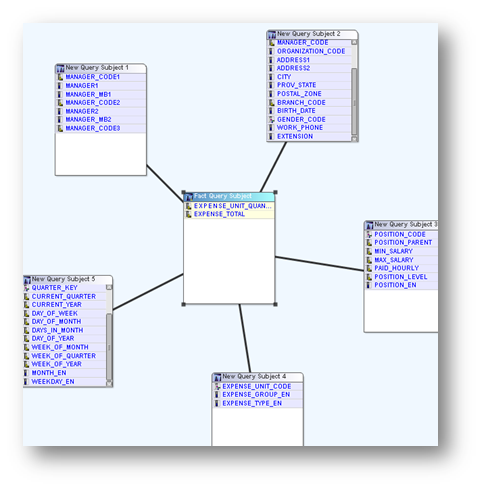
One of the basic tenets for best practice model design is to segment the model into four specific sections or layers (Data, Logical, Presentation and Dimensional). Each layer has a specific function and set of modeling activities. Generally, the layers build upon one another, with the data layer being the foundation of the model. Other areas, such as packages and connections are also important, but fall outside of the layers. Many of the best practices can be thought of in terms of what development activities should or should not be performed in each of the layers.
Data Layer
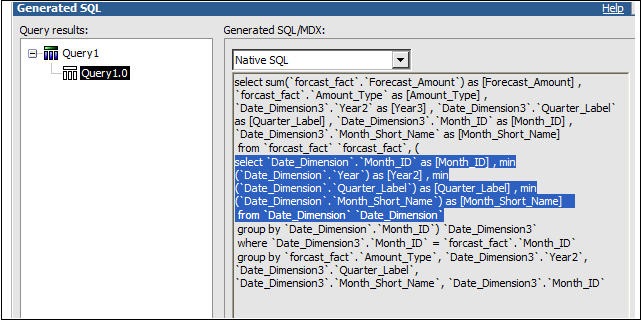
The data layer, also called the import layer, contains the data source query subjects, based directly on the underlying database objects. Whenever possible, use unmodified SQL ( “select * fromTable Name”)to retrieve the table information. If you modify the SQL code or add a filter or a calculation to the data subject, it eliminates Framework Managers meta-data caching capabilities. This means that Cognos 8 will validate the query subject at report run time, adding overhead to the report load time. In some circumstances, this may be worth the trade-off, but should be avoided when possible.
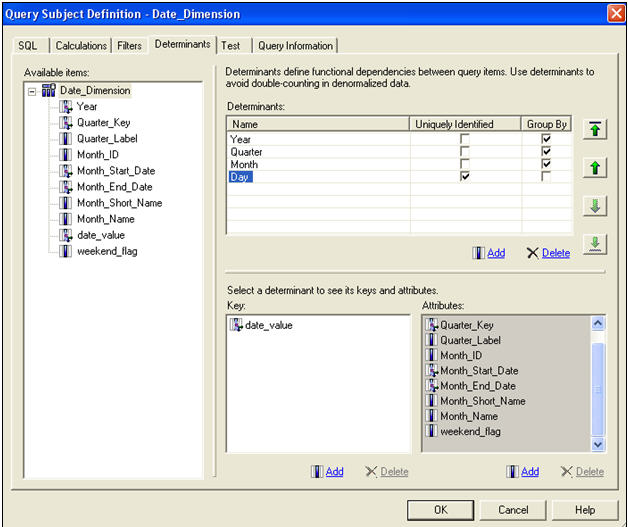
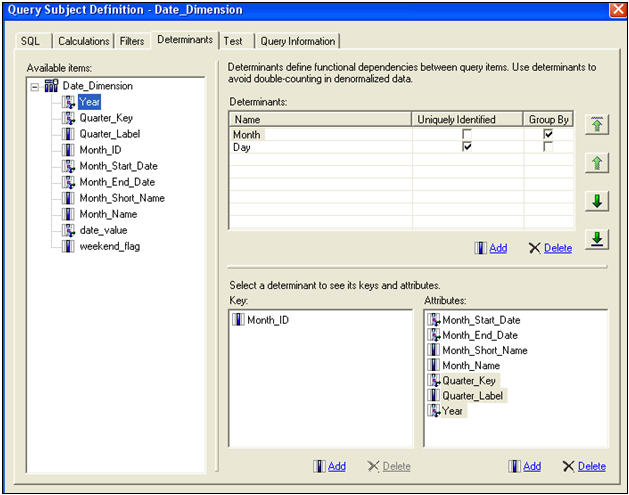
Add joins, cardinality and determinants at this level. Cardinality, the definition of how joins should behave, is critical to a well developed model and can be confusing, even to seasoned veterans. In lieu of a lengthy discussion within this article, consider other IBM
documents which offer a thorough discussion of cardinality, and the typical types of situations you may see.
Expect 20 to 40 percent of the model development to take place in the data layer.
Logical Layer
The logical layer adds the bulk of the meta-data to the model, and consequently is where most of the work is likely to occur. It provides business context and understanding to the data objects. Tasks include but are not limited to:
- Organizing elements into logical query subjects. This may mean combining elements from multiple tables, as in a snowflake dimension.
- Renaming element names, including descriptions and tooltips, and adding multiple language definitions if needed. Assign standardized and business-defined terms to the database columns, giving them business context.
Add calculations, and filters including stand-alone filters, embedded filters and security-based filters. Base these on the underlying data layer objects to make them less susceptible to errors when copying and reusing the query subject.
- Arrange query subject items in a user-friendly manner. Make use of folders to group similar items, or when there are too many items. I suggest 12 or fewer objects per folder, although I have used more when the logical breakout calls for it. For example, if there are many dates in a query subject, it might be more intuitive to have all the dates in a single large folder, than to try to subdivide each into smaller, random folders. Arrange the contents of the folder in an intuitive manner, such as alphabetic, or with the most commonly used items at top. HINT: It can be useful to use the “Reorder” command available within FM for this purpose.
- Assign output formats and usages to the reporting elements. This is easier if you create a small folder of trivial calculations, used only to provide standardized object format templates. The formats can easily be copied to target items by multi-selecting, and dragging the topmost format through the list.
- Add prompts, including cascading prompts, and prompt-based calculations.
Roughly 50 to 70 percent of the modeling work occurs in this section.
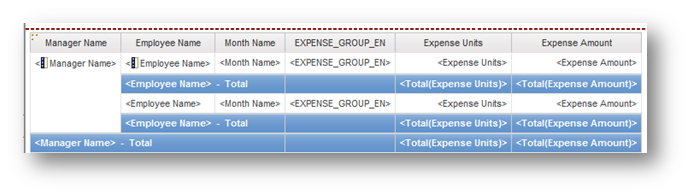
Presentation Layer
The importance of making information easy for report writers to use is frequently underestimated, but is a critical component to driving user adoption. Fortunately, this can be a simple step. The presentation layer is used only as an organization structure in order to make it easier for report writers to more easily find their needed information. This layer includes only shortcuts to existing items in the logical layer, plus organization items such as folders and namespaces.
For example, create a namespace called Orders and include shortcuts to the ten or twenty relevant query subjects, out of perhaps a hundred or more query subjects in the logical layer. Also include shortcuts to relevant filters. Commonly used query subjects (such as Items or Customers) will appear in multiple areas. Rename the shortcuts to something which provides helpful business context.
For organizing major groupings, you can use either folders or namespaces. However be aware that namespace names must be unique, and that items within a namespace must likewise be unique. So, if you use folders for your major groupings, you cannot have a shortcut named “Items” in more than one folder. You must rename them to unique names, such as “Order Items”. For this reason in particular, I generally prefer to use separate namespaces.
The presentation layer takes approximately 10% of the overall model design effort.
Dimensional Layer
The dimensional layer is required only for models which include dimensionally modeled data. Leaving aside the trivial situations where cubes are simply imported into the model, this includes dimensionally modeled relational data (DMR).
Specifically, this is for creating Dimensional and Measure Dimension Query subjects. Much like the presentation layer, this layer also is built upon the logical layer, which leverages the effort put into that layer. Apply the element renaming, descriptions, tooltips in the logical layer, and they can be reused in the dimensional layer, with some help from the search tool.
Finally, note that when you are creating the final package, you should hide the data and logical layers so that the user will only see the presentation and/or dimensional layers.
above described the overall approach for best practice model design using the 4 layer architecture. In this month’s article, I’ll describe some advanced issues which arise during model design, and how best to deal with them. Given the limitless and complex situations that can come up during modeling, these techniques may or may not apply to your specific situation.
Data Sources
One area which many modelers neglect is the data sources. A key part of the data source is the Content Manager Data Source, which references a data source configured via the web interface in the Administration area of Cognos Connection. You should have as few of these as possible, ideally only 1 per database, unless there are very specific reasons (such as security). Even so, many security or logon issues can be addressed via multiple connections or signons within a data source.
Framework Manager will automatically create multiple data sources, (one per schema, for example), but they should reference the same Content Manager Data Source. The reason minimizing these is because multiple Content Manager data sources will open separate connections to the database and force Cognos to perform simple joins within the reporting engine instead of in the database where they belong.
Relationships and Cardinality
The area which causes much confusion and difficulties with modeling is relationships and cardinality. There are a number of documents which discuss the handling of data modeling traps, such as theGuidelines for Modeling Metadata document included in the documentation, and so I will not duplicate those discussions here, instead addressing other topics.
A common concern is when to alias a table in the data layer. In general, common dimension tables used across multiple fact tables, or contexts, should not be aliased. This is important in creating conformed dimensional reports. For example, a parts dimension is the same when used for reporting against sales or inventory fact tables. When a table has separate usages, or meanings, it should be aliased. For example, a general purpose address table, which contains branch, customer and employee addresses. These are often identified by having multiple join paths or filters which can signal different usage.
Another situation to use aliases is when there are multiple usages of a dimension table. The most common occurrence of this is the general-purpose date dimension table. Applications such as health and insurance can have many different joins to a date dimension, each of which has a different context. This can be complicated to track, because one usage, such as Admission Datemust apply in a conformed manner to many fact tables, while a different usage (Treatment Date)must also be conformed across many of the same dimension tables. Obviously a meaningful naming convention is required!
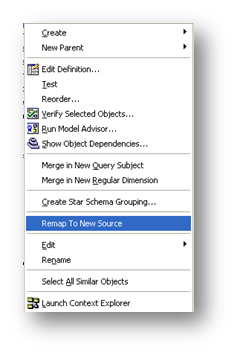
If you do decide that you’re logical query subject requires a different alias, make sure to make liberal use of the Remap to New Source option, available by right-clicking on the query subject.
Controlling Stitch Queries
One frequent point of confusion, is how the model causes reports to create stitch (or multiple) queries. To resolve this requires a firm understanding of the cardinality in relationships. Also realize that stitch queries are sometimes best way of issuing a query.
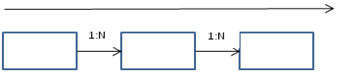
Report studio will generate simple, consistent queries when there is consistent progression from “1 to many” relationships. This is a smooth progression from dimensions to facts. It can easily generate facts with correct aggregations with this simple scenario. Remember that Cognos will treat the query subject at the end of one or series of 1:N relationships as fact tables.
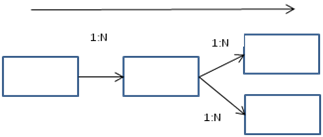
Similarly, it also works well in the case where multiple “dimensions” converge on a single fact table, as shown below. An easy visual check is to make sure that the 1:N relationships proceed in the same direction, with the ultimate fact table serving as the “Many” end-point of several dimensions.
The stitch issue occurs when there is more than one “Many” side along the same dimension path, as shown below.
A query which utilizes both of the rightmost, or “fact” tables will result in a stitch query as the only relationship is via a comnformed “dimension” table. In a query where i nventory (fact) and sales (fact) are compared at a product (dimension) level, a stitch query is the correct approach. However, if this is an unintentional or poorly modeled relationship, incorrect or inefficient queries will be generated. Understanding the implications of cardinality in relationships is the best defense against this.
Naming Conventions and Nomenclature
Another area of confusion is naming conventions and nomenclature, and areas surrounding these subjects. The best practice is to have the query subject and element names all carefully thought out and implemented before developing the model, but that doesn’t always happen.
First, let’s describe how Framework Manager and report studio considers element names. Each element name is uniquely identified within the package by a 3 part name: The element itself, the parent query subject (or shortcut) name, and the parent namespace to the query subject. Element names must therefore be unique within the query subject, and similarly for query subjects within the namespace. However, the namespace name must be unique within the entire model. So you can have multiple references to element “Part Name” within query subject “Part Master”, but the namespace, such as “Purchasing” or “Inventory” can only occur once within the model, making the fully qualified name unique. Notice that folder names do not come into play when defining names. They are used only for organizing other items.
Managing Name Changes
The result of all this, is that names within the model are very important, especially once report writing begins, because they are difficult to change without invalidating existing reports.
So, in order of preference, maintain consistent names across models by:
- Get it right the first time. If multiple areas of the organization have a stake in naming conventions, involve all organizations early in the design process, even if the first stages do not apply to some of them.
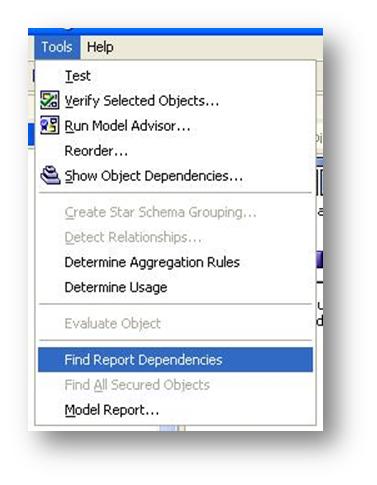
- Identify situations where a renamed item is used. Here the option “Find Report Dependencies” is invaluable in identifying reports where an item is used. Keep in mind, though, that if your model references a development server, it will not identify reports or queries which exist only in your production environment. Therefore it may not adequately identify issues in every environment.
- Move the renamed item to a “deprecated” query subject folder, and create a similar element with the new name. While this relies on a certain amount of end-user training, to instruct report and query writers not to use objects within a folder named “DO NOT USE” or similar, it will ensure that existing reports will still run correctly, while using the new, correct name moving forward.